
GitHub 更新一项实验版新功能。用上机器学习后,新版 CodeQL 代码扫描服务可以帮开发者发现更多安全漏洞。
目前在 JavaScript 和 TypeScript 存储库上开发测试,以后会逐步增加各种语言支持。
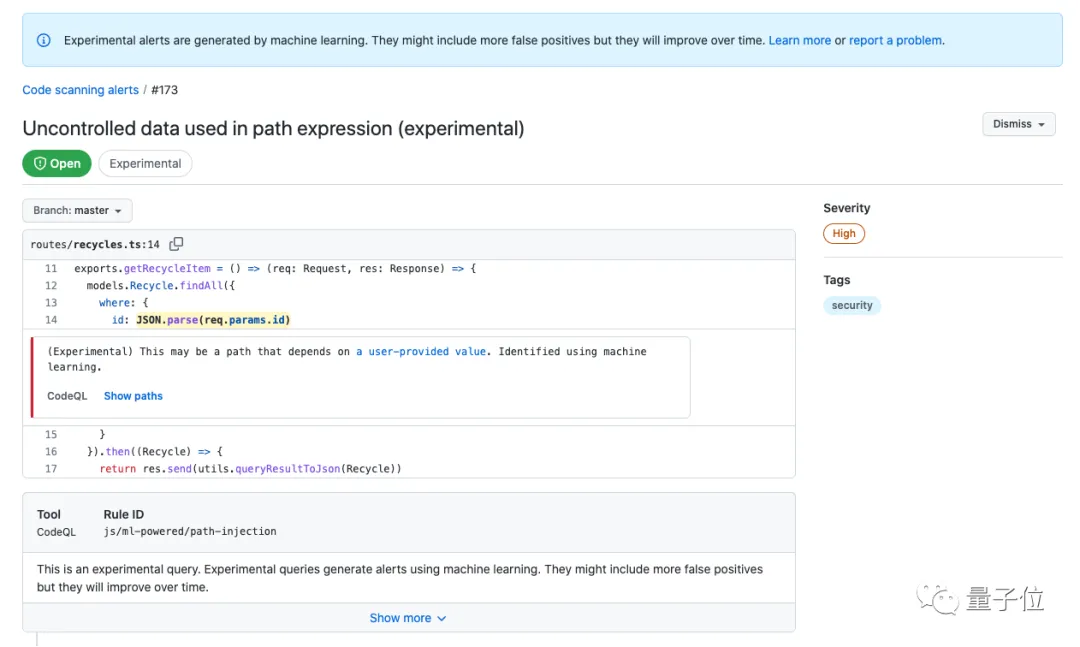
在测试期间,CodeQL 已经从 12,000 个存储库中发现了超过 20,000 个安全问题,包括远程代码执行(RCE)、SQL 注入和跨站脚本(XSS)漏洞。
如何使用
GitHub 的 CodeQL 代码扫描对于公共存储库是免费的。
目前,新的 JavaScript / TypeScript 分析工具,已向 security-extended 和 security-and-quality 分析套件的所有用户推出。
如果你已经在使用这些套件,那么将自动使用新的机器学习技术进行分析。
如果你之前没使用过,可按照以下步骤启用 CodeQL。
在你的存储库主页下,单击 Security。


在 Code scanning alerts 右侧,点击 Set up code scanning。如果缺少这一项,需要由存储库管理员启用 GitHub 高级安全性。


在“Get started with code scanning”下,单击在 CodeQL Analysis 中的 Set up this workflow。


使用 Start commit 下拉菜单,输入文件名并提交。


选择直接提交到默认分支,还是创建一个新分支并启动拉取请求。


单击提交新文件。


代码扫描分析成功后,用户将在“Security”选项卡中看到安全警报信息。
为何用 ML 能产生更好效果
为了检测存储库中的漏洞,CodeQL 引擎首先构建了一个数据库,对代码的特殊关系表示进行编码,然后在数据库上执行一系列 CodeQL 查询。
但随着开源生态系统的快速发展,长尾效应越来越明显。
安全专家不断扩展和改进这些查询,对其他常见库和已知模式进行建模。然而,手动建模很耗时,而且总会有一些无法手动建模的不太常见的库和私有代码。
这时候机器学习就派上了用场。通过给定大量训练代码片段,每个查询都标记为正面或负面样本,为每个片段提取特征,并训练深度学习模型对新示例进行分类。


GitHub 不是将每个代码片段简单地视为一串单词或字符,直接应用标准 NLP 技术对这些字符串进行分类,而是利用 CodeQL 访问有关底层源代码的大量信息,为每个代码片段生成一组丰富的 feature,然后像 NLP 那样对它们进行标记和子标记。
由此从训练数据中生成一个词汇表,并将索引列表输入到深度学习分类器中,输出当前样本是每种漏洞的概率。
虽然现在基于 ML 的漏洞扫描仅适用于 JavaScript / TypeScript,但 GitHub 承诺未来会支持更多语言,现在 CodeQL 已经支持了 Python、Go、C / C++ 在内的多种流行语言。
最后,GitHub 还强调,虽然全新工具可以发现更多漏洞,但也有可能提高误报率(召回率约为 80%,精度约为 60%)。未来这项功能会随着时间推移而改善。
图文@量子位
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 